
Intro
Machine Learning (ML) is an extremely complex area of computer science that unfortunately cannot be limited to one straightforward definition. To understand its essence, start with looking at the Machine Learning stack as a complex multi-layered system with interlinked components. Each component has its specific role and position defined by the ML software hierarchy. Today, we are focusing on the types of machine learning algorithms — fundamental elements of AI computing.
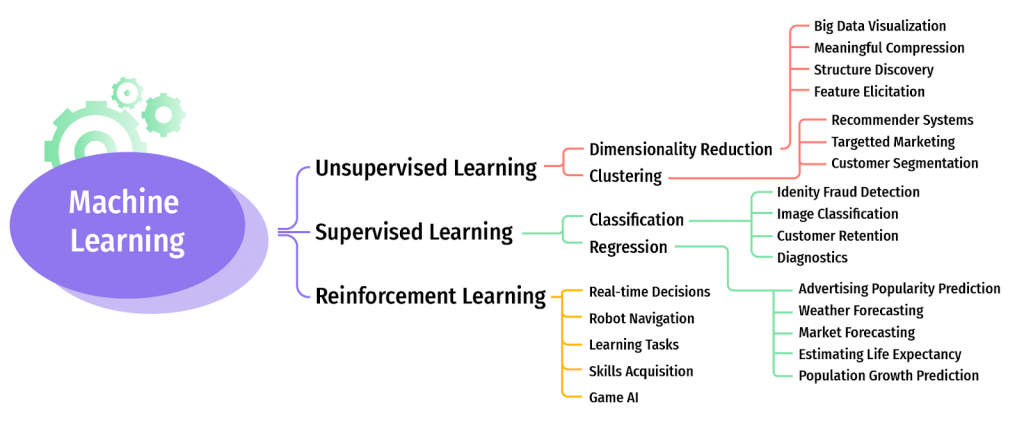
Machine Learning Types Explained
The idea behind machine learning is to give the software an ability to progressively improve its performance through programming and mathematical modeling. Although ways of defining ML are numerous and totally depend on the approach, whether it’s scientific, programming or even marketing, starting to explore the machine learning algorithm types is a secure option for one seeking ML expertise. Most frequently, the categories ML types fall into, include the following:
- Supervised learning;
- Unsupervised learning;
- Reinforcement learning;
- Semi-supervised learning.
Supervised Learning
Supervised learning is the type of ML algorithms that presupposes both input and output data is initially provided. Basically, data engineers create an algorithm, then train it with a labeled dataset — the one that has actual input and output parameters. The result of a quality training process is the ability to pick a function that gives the processes the input data in the most adequate and accurate way, as it was sampled in the training dataset.
In most cases, the way an ML network interacts with the loaded data remains unrevealed even for the engineers who created it themselves. One sure thing is that the system that learns through supervision starts its performance by relying on human assumptions implemented in code. In simple terms, the team of professionals (programmers and data engineers) acts as a singular tutor demonstrating the network answers to typical questions/tasks/situations, thereby forming a behavioral pattern in it. Based on what the network has learned, it becomes able to build predictions and deliver results itself. Supervised learning systems are mostly associated with retrieval-based AI but they may also be capable of using a generative learning model.
Supervised ML algorithms divide into the following subtypes, depending on the tasks they deal with:
- Classification. This is a kind of algorithm that relies on certain defined labels in the output data. For example, if you want a software that, for example, predicts whether a person would click the link in a marketing email after reading it, first you have to provide possible outputs with their discrete value (in our case, this could be yes or 1 for clicking the link and no or 0 for not clicking). After you give the software a starting point in the form of a history of people who clicked the link with the corresponding information about them classified accordingly, the program will be able to predict the discrete values of these two classes (positive potential customer behavior and the negative one). Classification ML type can be binary, when a machine chooses from two possible predictions, and multi-class, when there are more than two answers to choose from.
- Regression. That’s a subtype of classification algorithm that solves tasks with continuous discrete data, meaning the one that cannot be framed in a certain range. Regression-based ML algorithms evaluate the possible outputs together with processing the possible error value. This means the level of data processing accuracy depends on how small the error is.
Some other subtypes of the supervised ML learning algorithms include:
- Linear Regression
- Support Vector Machine (SVM)
- Gaussian Naive Bayes
- Nearest Neighbor
- Decision Trees
- Random Forest
Unsupervised Learning
Unsupervised learning is a type of algorithm which works with the input data having no examples or suggestions of the expected output. Its primary aim is to distribute the data into categories so that the output would be more informative compared to the loaded input. The term unsupervised means that there is no supervisor who could tell the system right answers, in fact, there are no right or wrong answers in the first place.
Unsupervised algorithms are used to discover some characteristics in the data under its analysis that aren’t obvious, or in some cases truly surprising, for the data engineers and ML programmers. Training of an unsupervised learning algorithm is organized in the following way: the machine gets fed with training data that isn’t labeled or structured in any way so that the algorithm could interact — usually, sort and classify — with this data up to its own logic. The aim of the ML model here is to detect some similar traits in data units it was loaded with and sort them accordingly. An example of an unsupervised ML algorithm in action could be software that detects, for example, different kinds of fruit or animals: a properly trained network will put bananas and apples into two different categories and it will do it despite seeing this particular fruit for the first time ever.
Unsupervised learning divides into the following subtypes:
- Association. This ML subtype is basically making assumptions about some parts of the data proceeding from its characteristics we already know. This allows discovering fascinating interconnections between portions of data in large datasets.
- Clustering. This kind of algorithm is very spread since it allows simply grouping the pieces of data according to a certain trait.
Reinforcement Learning
This Machine Learning type has been booming in the past few years, and the public interest to it doesn’t seem to decrease anytime soon. It is a kind of learning that allows an autonomous agent to navigate through a dynamic environment while balancing the state, actions, and environmental rules and aiming to achieve the maximum numerical reward. The framework of this one is actually quite similar to the classic supervised learning algorithm type. We have a data input layer that goes through some hidden neural network layer and delivers the result as an output. The difference here is that although we have a very approximate image of the output that we want to be produced by the network, we can’t label it, because this would limit the potential of the whole ML model. With reinforcement ML type, the network transforming input frame into output action is called policy network.
The training of such ML starts with a completely random set of actions that’s loaded to an environment (let’s say a video game engine) for the network to explore the environment. As the actions change, so as the network, namely by adapting to the change and realizing it’s not going to be the same action every time, just like it’s not going to be the same state every time. Over time, the network discovers good and bad behaviors and analyzes what kind of behavior draws higher rewards. From that description, you might have already guessed it was up to reinforcement learning the AI managed to win pro’s on Dota 2 and Go.
Real-life applications of reinforcement ML includes data processing, robotics, simulation models, and analytic solutions for the known environment as a part of process automation.
Semi-Supervised Learning
Although the traditional classification pf ML algorithm types ends by the three ones we mentioned above, the list wouldn’t be full without putting the semi-supervised learning on it. This type was developed with the aim of minimizing some major disadvantages of both supervised and unsupervised learning. Namely, supervised ML can cost a fortune since it’s simply impossible without a handcrafted dataset, meaning — hours of work of data scientists or ML engineers. With unsupervised learning, the number of technical tasks it can solve is rather limited.
With semi-supervised machine learning, the network is trained with a combinatory dataset consisting of both labeled and unlabeled data. Usually, there is a small percentage of labeled information combined with a very large amount of unstructured data. That way, a learning algorithm can label all the unlabeled data without human interaction just by relying on the initially labeled pieces.
Summary
We hope you got an idea of what are some of the fundamental Machine Learning algorithm types. If not, our team is always one click away ready to answer all your ML-related questions and beyond that!
 (4 votes, average: 5.00 out of 5)
(4 votes, average: 5.00 out of 5)