Intro
Artificial Intelligence is one of the most important technological advancements humanity has seen in recent history. Just a few decades ago, it was hard to believe that Machine Learning — a flagman subset of AI — will power so many things in our daily life, making it easier and better. So, it’s not much of a wonder that even non-tech people are actively searching for this topic. Let us introduce you to our epic longread on Artificial Intelligence and its subsets that wraps around the AI/ML-related articles in IDAP blog. Make yourself comfortable, grab a drink, and get ready to become a little smarter in the next 20 minutes.
Chapter 1. Machine Learning: Theory
Artificial Intelligence & Machine Learning: Is It The Same Thing?
To say it shortly, Machine Learning isn’t the same as Artificial Intelligence. In fact, AI refers to a way wider term from Computer Science. Machine Learning is actually one of AI subsets, in other words, it’s just one of the methods to achieve the autonomous intelligence in machines. Alongside ML, there are a lot of other methods of achieving some of the human intellect capabilities, like Artificial Neural Networks, Natural Language Processing, and Support Vector Machines.
Summing it up, think of AI as of any technique that allows machines to mimic human intelligence, namely — demonstrate autonomous learning, reasoning, decision-making, perception, data analysis, etc. In its turn, ML is a specific method of AI with its technical characteristics and ways of functioning.
Machine Learning vs. Deep Learning
Deep Learning is another subset of Artificial Intelligence. Although it is similar to ML in terms of functions and belongs to the Machine Learning algorithms family, yet still it is unique in architecture. DL is based on artificial neural networks inspired by the human brain and its cells — neurons. The artificial neurons receive input information and transform that input according to whatever example demonstrated to the network. Every neuron in a chain is connected to another so that it can transmit the signal.
Deep Learning networks are multi-layered in structure, and for engineers, it’s only visible how the network processes data on the first (input) and the last (output) layers. The rest remains unseen and is called hidden layers. The more hidden layers are in the network, the more accurate are the results of data processing (although extra hidden layers take more time for processing).
The introduction of artificial neural networks has revolutionized Machine Learning methods and the AI field in general. Modern DL algorithms deliver error-free performance, so the industry came to the state when no machine learning technique works without the Deep Learning function. Using these two terms interchangeably isn’t always right, however, DL fully belongs to the ML stack, so there’s not much of a mistake to call a Deep Learning network a Machine Learning one. At the same time, Machine Learning can be implemented without artificial neural networks, as it used to be decades ago, so watch the network structure before going for DL term.
Read Also: Machine Learning vs Artificial Intelligence vs Deep Learning
Machine Learning: Definition
Machine Learning is a Computer Science study of algorithms machines are using to perform tasks. Algorithms are rules that administer specific behavior, in our case — the behavior of a computer. Regardless of how complex one or another algorithm is, it can be broken down to If X happens, do Y action.
Smart or not really, algorithms run in every computing machine out there. So where does regular programming end and Machine Learning start? Machine Learning is when a machine can process the algorithm it runs on and improve it through learning. By loading ML-enabled computers with bytes of data, software engineers push them to improve their performance and achieve better results, meaning — zero errors in the input data processing. This technology is a necessity for software that’s aimed at solving tasks that cannot be defined by strict instructions, like predictions based on data analysis, email filtering, autonomous analytics, etc.
Saying it shortly, Machine Learning is a set of algorithms that a computer program abides by and learns so that it’s able to think and behave in a human-like manner, self-improvement included.
Machine Learning Types Classification
1. Supervised Learning
Supervised Learning is the most straightforward concept. This type of ML assumes the expected output of data is demonstrated to the network before it gets to processing the input. In other words, data analytics show the ML algorithm what exactly it has to find in the data loaded. For example, in computer vision programs that analyze traffic and parking lots, engineers use images of labeled cars as a training dataset. Training datasets consist of hand-picked information that was labeled accordingly for the network to understand it. Regardless of ML type, the training process is extremely important as it enables the network to work in the future. This is the most time-consuming process out of all the others in terms of ML software development as well.
Supervised Learning is capable of many tasks, but mostly it is used for classifying and predicting things based on supervision data provided. Types of Supervised Learning includes Classification and Regression with further division into dozens of specific algorithms depending on the input data. For example, linear regression for linearly separable data and kernel methods (support vector machine) for non linearly separable data among others.
2. Unsupervised Learning
Unsupervised learning is a kind of ML algorithms that works without sampled outputs of data. Primarily, this type of learning is used to make data more informative, find correlations between different input classes that aren’t noticeable for humans. The key difference of Unsupervised Learning from the Supervised one is in fact that there’s no training dataset provided and an Unsupervised network rather interprets input data instead of following an analysis pattern.
Unsupervised Learning divides into two fundamental algorithms types — Association and Clustering. The Association-based algorithms are used for making assumptions based on what the network already knows about the input data thereby extending the information. Clustering algorithms group smaller pieces of data according to common features that they themselves have identified through analysis of a large dataset.
3. Reinforcement Learning
Reinforcement Learning is a type of Machine Learning algorithms aimed at solving tasks and taking choices, preferably — only the right ones. The essence of this kind of ML is in the reinforcement learning agent, which learns from experience gained in the past. Basically, this autonomous agent starts with random behavior to get some starting point for collecting examples of good and bad actions. It navigates in a certain environment and studies its rules, states, and actions around it. Through such a trial-and-error set of actions it learns to interact with the environment it’s in, solve its tasks, and reach the maximum numerical reward.
Reinforcement Learning has drawn way more attention than any other ML type, mostly because this is the most spectacular if not mind-blowing kind of algorithms. It powers AI bots that defeat world champions and e-sports and the Go board game. It acts in a way that looks like intuition and human-like attitude towards problem-solving. The absence of any learning material combined with dramatic complexity of tasks in RL programs’ power makes Reinforcement Learning the most fascinating and ambitious area of Machine Learning.
4. Semi-Supervised Learning
Semi-Supervised Learning is a hybrid type of Machine Learning that is aimed at minimizing the drawbacks associated with the Supervised and Unsupervised ML categories. By mixing up these two, software engineers achieved technical diversity in terms of applications while saving time and budgets for product owners. Semi-Supervised solutions rely on combinatorial datasets for training. Such datasets consist of both labeled and unlabeled data with the unlabeled pieces leading the ratio. The thing is no matter how much of the unlabeled data is there waiting to be processed, after the network has gone through the labeled pieces, it can successfully interact with the rest of the dataset.
Machine Learning Industry In Numbers
- Machine Learning tops the AI industry in terms of funding:
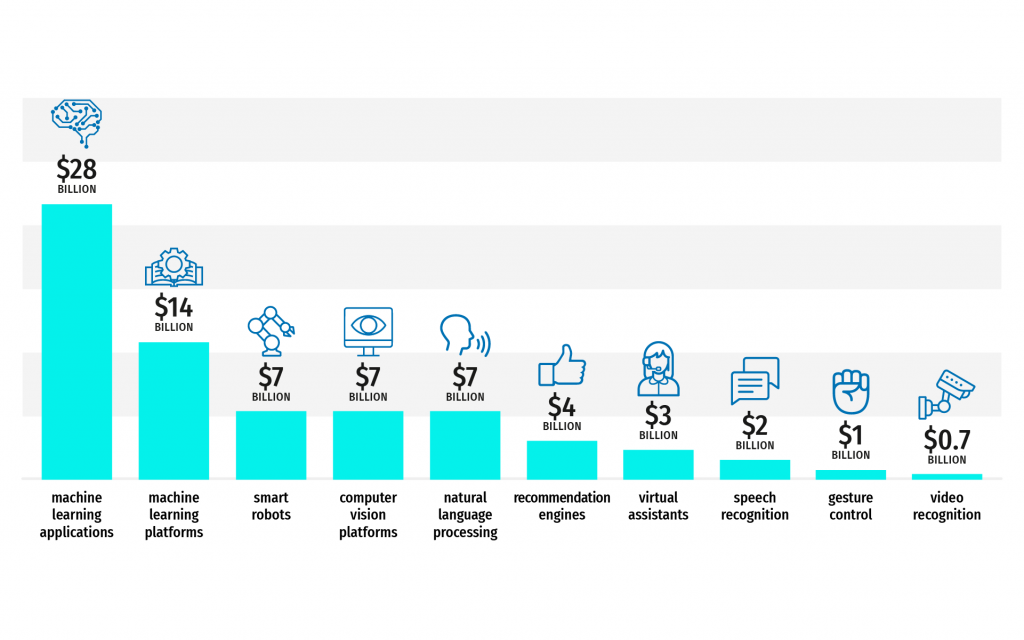
- 61% of chief entrepreneurs point to AI and ML as their major technical initiative for the next year (source).
- 27% of executives plan to invest in cybersecurity solutions powered by AI/ML tech (source).
- AI and its subsets are expected to replace 16% of U.S. jobs by 2025. Office and administrative support staff will be the most rapidly disrupted (source).
- AI use for business operations can increase office productivity up to 10% (mckinsey.com).
- 15% of organizations position themselves as advanced ML software users (mckinsey.com).
- 80% of companies are going to assign the customer service activities to AI software by 2020 (oracle.com).
- When AI is used in commercial operations, 49% of consumers are willing to shop more often while 34% will spend more money (PointSource).
- Google Translate’s algorithm accuracy increased from 55% to 85% after implementing Machine Learning (arxiv.org).
- 95% is the accuracy of Machine Learning in a patients’ death prediction (bloomberg.com).
- 62% is the accuracy of Machine Learning in predicting stock market highs and lows (microsoft.com).
History of Machine Learning: 18th to 21st Century
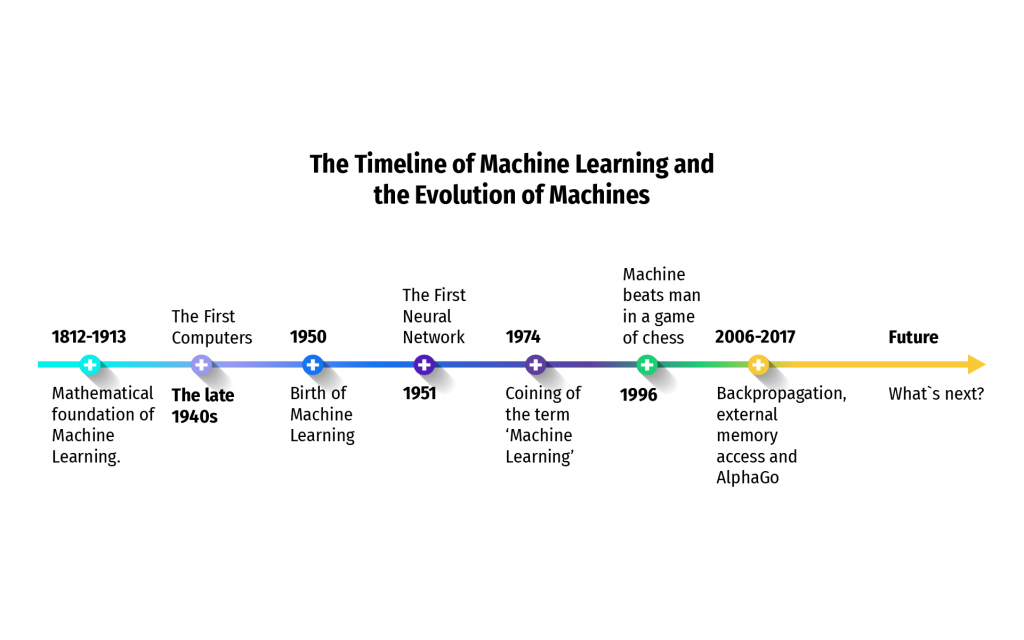
Believe it or not, it was back in the beginning of 19th century when the foundation of Machine Learning was laid. The general interest of scientists in Math and such achievements in this field as Markov chain and Bayer’s theorem acted as true groundwork for the future of ML.
In the late 1940s, the world has seen the first computers starting with ENIAC — Electronic Numerical Integrator and Computer. It was a general-purpose machine that could store data and even perform a large (at the time) class of numerical tasks. This huge machine was initially designed and created for the US Army’s Ballistic Research Lab, but later it was moved to the University of Pennsylvania. A few years later the famous Manchester Baby, also known as the Small-Scale Experimental Machine was made.
The birth of Machine Learning as we know it today happened in the 1950s. The very first artificial neural network was created in 1951 by Marvin Minsly and Dean Edmonds. It contained 40 interconnected artificial neurons and was aimed at solving a maze. The term was introduced to the public in 1959 by Arthur Samuel from IBM, however, the debate over machines that think had been around since the very start of the decade.
The 1960s weren’t too fruitful in terms of AI and ML studies except for the 1967. It was the year of the nearest neighbour creation — a very basic pattern recognition Machine Learning algorithm. It was initially used for map routing and later became a basis for more advanced pattern recognition programs. In 1973, two scientists Richard Duda and Peter Hart released a fundamental study Pattern Classification and Scene Analysis. Till the beginning of the 1980s, there wasn’t much progress in AI field.
In the 1980s the Machine Learning subfield outgrew the AI area of science into the independent field. In 1981 Gerald Dejong introduced the Explanation Based Learning concept, which is very similar to the Supervised Learning idea. In particular, a machine running on EBL algorithm could analyze training data and compile general rules it was arranged for. Back then, it was reported that a computer can recognize 40 characters from the terminal. Terry Sejnowski brought a lot to the field with his studies and inventions in Computational Neuroscience, for example the NetTalk application which used ML algorithms to help interpreting human speech impairment.
Although the 1990s didn’t bring much to the Machine Learning field in general, it was an era when public interest to AI applications started growing even in non-tech people. The two most spectacular events on that matter took place in 1996 and 1997 correspondingly. In 1996, at the time world chess champion Garry Kasparov played a chess match with IBM’s Deep Blue computer powered with ML algorithms. The human player proved his champion status and defeated the Deep Blue. However, in 1997 the IBM’s machine took his revenge on Kasparov and won the match. It was the first unbeatable proof (and a very vivid one) of a computer being as good at some cognitive activity as a human being. Since then, this area of science started to develop at an exponential rate.
As the 21st century came around, Artificial Intelligence and Machine Learning became the it-words for the world of technology. AI startups raise enormous investments, businesses are finally ready to splurge on ML solutions for their operations, and Data Science field is generating job openings here and there. The largest projects in the area include GoogleBrain and AlexNet for image computer vision, DeepFace created by Facebook for accurate face recognition, DeepMind video games player simulator that defeated the world champion in the Go board game and was acquired by Google in 2014, and OpenAI — non-profit platform created by Elon Musk and his team to help people develop life-enhancing AI products.
Chapter 2. Practical Aspects of Machine Learning Field
How Machine Learning Actually Works
The work of Machine Learning-powered software divides into multiple simultaneous processes that differ drastically from one solution to another. That’s why to give you a clearer image of how artificial models and networks actually do their job, it’s better to narrow this conversation down to a single example of ML product.
So let’s say we’re looking at an artificial neural network for an automated image recognition, namely — we want a program to distinguish a picture of a human from a picture of a tree. Computers in general perceive the information in numbers, and so as ML software. To a machine, a picture is nothing but a table of numbers that represent a brightness of pixels. Meaning, each pixel corresponds to a particular number depending on how bright it is, let’s say 1 for plain white, -1 for total black, 0.25 for a light grey, etc. As you can see, although there’s a term computer vision in use, computers do not actually see, but calculate. An ML network evaluates the pixels of the input picture, summarizes their numerical value and calculates its weight. That weight of the input data piece is what people call a whole image — from that, we can say what is depicted there.
Getting back to a human vs. a tree categorization task, the network will distinguish these two categories depending on the weight of each input image. But what’s the weighted sum of a human pic and what’s it of a tree pic? In other words, how our artificial network will find out what makes a human human and what makes a tree tree? The answer here is training process. The training process in our case would be arranged as follows: we show the network examples of both categories of pictures and allow it to adjust their pixel weights to come up with a template. Adjusting means that the network will polarize the weighted sums to achieve the higher contrast between the human pictures vs. tree pictures. In other words, after we showed a labeled picture of a person to the network, we then command to decrease its weighted sum so that it’s less than 0. Correspondingly, labeled pictures of trees get their pixel weights increased to a constant more than 0 value. That way, the network gets a secure template to abide by: human pic means less than 0 and tree pic means more than 0.
The basic unit of modern artificial networks is neuron. Since any Machine or Deep Learning solution is a mathematical model in the first place, artificial neuron is a thing that holds a number inside it as well. Inside the network, neurons are located in a layered structure. These layers are the receptive fields of the network, or in other words, that’s where all the magic happens. The more layers are in the network, the more accurate results it delivers.
Some of the other real-life examples of Machine Learning use, that by the way have already had their moment on our blog, include speech recognition as in virtual assistants, dynamic data analysis as in trading, customer relations management, and even healthcare, and robotic automation as inside the Amazon warehouse.
Will ML Replace Traditional Programming?
In a word, no. Machine Learning will not replace traditional programming. Extending the answer, let’s look at how these two actually differ from one another. Traditional programming refers to a manually developed software that performs due to the data processing algorithm implemented in code by a person. The output result wouldn’t be possible if there were no human engineer in the first place. As for the ML, the output itself here does not require human interaction, in other words — the working processes of ML models are fully automated. However, this does not makes Machine Learning suitable for every technical task out there. No software developer will use an ML algorithm to create a website or mobile application. Of course, some AI subset can be a part of a software product to enhance its performance but the general rule is the following: ML stack comes in hand only in case traditional programming is ineffective. The mainstream ways of implementing software UI components show no tendency for a change.
Custom ML Software Development
Although there are some quite powerful ML distribution platforms on the market, entrusting all your business operations data and relying on someone else’s service aren’t for everyone. That is the first reason why many entrepreneurs look for teams who specialize in custom ML solutions development and want to find out what stands behind Machine Learning in terms of stack.
Programming languages for ML
Ten most popular machine learning languages are Python, C++, Java, C#, JavaScript, Julia, Shell, R, TypeScript, and Scala. Python has become more popular compared to the other options because of its accessibility, diverse libraries such as PyTorch and TensorFlow, and ease of learning with tons of free online resources. Java is also a good option, especially due to the strong community around this language. R and C++ are the last spread options, though still attention-worthy programming languages. They’re followed with options that are rarely found in real-life use cases.
Machine Learning Libraries
1. Scikit-learn
A free software ML library for solutions designed in Python language. It includes a wide variety of algorithms from classification to regression, support vector machines, gradient boosting, random forests, and clustering. Initially designed for engineering computations, it can be used alongside with NumPy and SciPy (Python libraries for array-based and linear algebraic functions). This library is especially popular amongst beginners due to its ease of use and compatibility with various platforms like CPUs, GPUs, and TPUs. It allows programmers to use preset data-processing models and supports the vast majority of standard ML algorithms.
2. TensorFlow
An open-source Python library for high-performing computations like ML and DL solutions. TensorFlow was developed by Google Brain AI team and was initially aimed at internal use. As the performance of the library progressed, the company decided to release the second-gen version to the public. Frequent use cases include differentiation and dataflow tasks. TensorFlaw’s flexible architecture and compatibility with a large number of platforms (CPUs, TPUs, and GPUs) delivers easier deployment of computation. This library is most known for its best-in-class computational efficiency and effective support of Deep Learning neural networks.
3. Keras
A user-friendly modular Python library for Deep Learning solutions that can be combined with the aforementioned TensorFlow by Google or, for example, Cognitive ToolKit by Microsoft. Keras is rather an interface than a stand-alone ML framework, however, it’s essential for software engineers working on DL software. It allows for fast interplay between neural network processes and gives access to numerous implementations of neural network layers, objectives, functions, as well as tools that optimize the working process with text and image input data.
4. Pandas
This Python software library is specifically designed for data analysis and manipulation practices, in other words, for the data gathering and training preparation steps in the ML software development. It is capable of collecting and structuring data from any source being it text, MS Excel file, JSON or SQL DB. It also has lots of diverse statistical functions on board, which can be used to analyze the gathered data and make it more useful for other libraries in the future.
ML Providers
1. IBM Watson
Watson is IBM’s platform that distributes ready-to-use AI applications, services, and tools. Along with its products, IBM also gives its clients the computation capacity for the software to run on, which solves the expensive burden of locating it in the cloud. As for now, Watson is the most diverse and technologically advanced company in terms of AI subsets offers. You can find the following solutions among Watson’s APIs and pre-built apps:
- Visual Recognition
- Text to Speech
- Language Translator
- Natural Language Classifier
- Personality Insights
- Tone Analyzer
Beyond that, there are also a few versions of the Watson’s AI Assistant specifically targeted for customer relations management, cybersecurity, and financial services. Although the range of the product looks really diverse, the drawback of all ready-made solutions is still there — not every business can fit their needs into an existing framework perfectly. The pricing for the Watson’s services varies, as it depends on the scale and exact products purchased. In any case, IBM is an absolute market leader that realizes its position on the market and charges accordingly.
2. Amazon Web Services
AWS is a cloud computing platform that offers businesses AI and ML services in a form of scalable suite. Launched in 2002, 17 years later it offers nearly a hundred cloud services. In addition to ready-made apps and tools, it also distributes a service that helps build, train, and deploy custom Machine Learning models called Amazon SageMaker. In range of SageMaker stack, you can surf through the algorithm marketplace, automate ML training and testing, and drastically simplify the deployment process of the finished model. Products range includes:
- Amazon Personalize for targeted recommendations;
- Amazon Forecast for analytics-based predictions;
- Amazon Rekognition for image and video analysis;
- Amazon Comprehend for advanced text analytics through natural language processing;
- Amazon Textract for document analysis;
- Amazon Polly for automated voiceover;
- Amazon LEX conversational agent;
- Amazon Translate for machine translation;
- Amazon Transcribe for transcriptions.
Other than software, Amazon platform also sells a few hardware pieces that demonstrate ML use in real life. For example, AWS DeepRacer is an autonomous racing car that positions itself as a learning tool for reinforcement learning and autonomous driving studies. On their official website, Amazon states that about 80% of all cloud Deep Learning models run on AWS.
Despite its robust infrastructure and seemingly limitless potential, AWS has its disadvantages and limits. Along with powerful solutions comes rather high pricing plan, as well as some common issues associated with moving to the cloud — downtime, limited control, and high dependence on the service provider.
Summary
The field of Machine Learning is no easy topic to learn about. The deeper you dive, the more questions arise and the answers are getting only more puzzling. As an independent provider of technical solutions powered by Machine Learning, we know that struggle from inside out. In case you ever need a tech consultation, IDAP team is just one click away so do not hesitate to schedule one. Also, stay tuned for our future publications on AI and its subsets we’re working on already.
 (1 votes, average: 5.00 out of 5)
(1 votes, average: 5.00 out of 5)